The dawn of Big Data

Over the past three decades, computing systems have seen relentless growth in features and performance, leading to the continued development of applications that rely on these systems to process and store data. In fact, improvements in hardware and communications networks have broadened the scope and dimensions of "data-reliant" applications (from the classic file servers to the Internet, and other fields such as robotics or automotive). This evolution has also meant that users’ demands when it comes to these systems have also grown over time; for example, today it would be unacceptable to have to wait 30 minutes to listen to a song downloaded from the Internet.
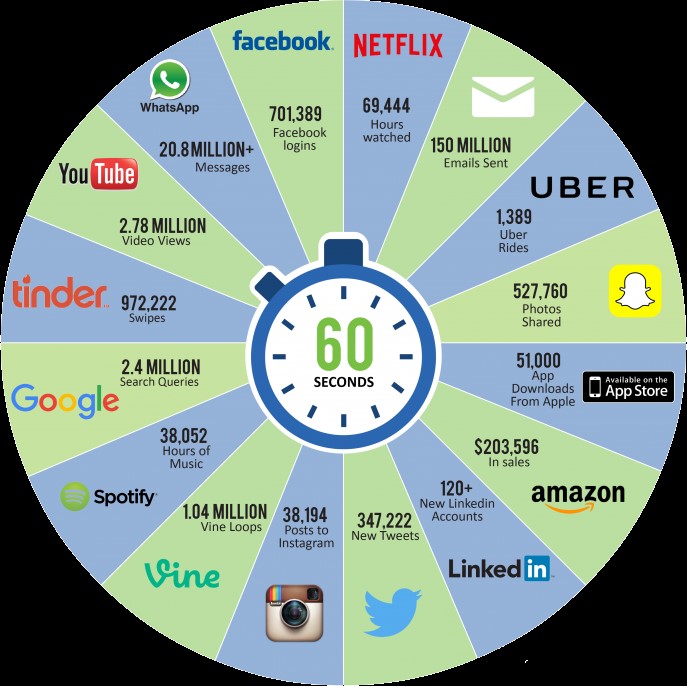
Historically, user requirements have grown proportionally with the technology available at the time: there has always been a bigger box to help pack a bigger new problem. In recent years, however, the amount of data processed on a daily basis has skyrocketed to such an extent that traditional techniques for processing and storing information are rapidly becoming obsolete. For example, it is said that in one minute: 72 new hours of video are uploaded to YouTube, 100 terabytes of information (notifications, page views, photos, clicks, etc.) are stored on Facebook, about 500,000 tweets are generated on Twitter, 200 million emails are sent and 350,000 photos are shared via Whatsapp. In short, if you count the amount of data that passes between us throughout the day, the results are astonishing.

This new order of magnitude in data has led to the definition of the Big Data concept. In general, this term is said to refer to any data set that satisfies 3 key concepts: Volume, Speed and Variety (some authors are now talking about 6 key concepts, adding Truthfulness, Visualisation and Value to the three previous ones). Since these three (or six) parameters depend on the nature of each problem, we see great confusion about the implications and scope of the concept of Big Data. In fact, Big Data does not just refer to the data itself, but also includes the entire engineering, research and business development aspects relating to storing, processing and extracting valuable information from an enormous amount of data. This text aims to shed a little more light on this concept (1) by explaining what led us to coin the term Big Data, (2) by emphasising why Big Data is so different from traditional data management systems and (3) by pointing out the opportunities that Big Data opens up for new data engineers and scientists.
In my opinion, Big Data is motivated by two major facts: the increased bandwidth of Internet connections (ADSL has done away with the 56Kbps modems of just a few years ago) and the rise of smartphones (it is estimated that 1 in 3 people around the world has a smartphone). The combination of these two factors means users happily install more and more applications on their phones, unconsciously generating an infinite amount of data day and night (calendars, messaging, social networks, games, etc.). Furthermore, these users, who are typically unaware of the technological complexities involved in processing so much information, expect and even demand high-quality service and have very little tolerance for disconnections (it is estimated that Facebook lost $500 million in ads due to a 30-minute service drop), all of which complicates the work of the architects behind these systems.
Despite the latest technological advances, system architects designing infrastructures to support Big Data have come up against two limitations: Internet bandwidth and distributed data storage.
On the one hand, it is faster to send 100 hard drives with 1 terabyte of information (remember, that’s just 1 minute of information generated on Facebook) coast to coast in the United States using a messaging company than by sending the data over the Internet. This limitation in Internet bandwidth has inverted the old paradigm in distributed systems according to which bringing the data (historically, a low volume) to the computer device (traditionally, more expensive); with Big Data, we aim to bring the computer device (now cheaper) to where the great volumes of data are being generated.
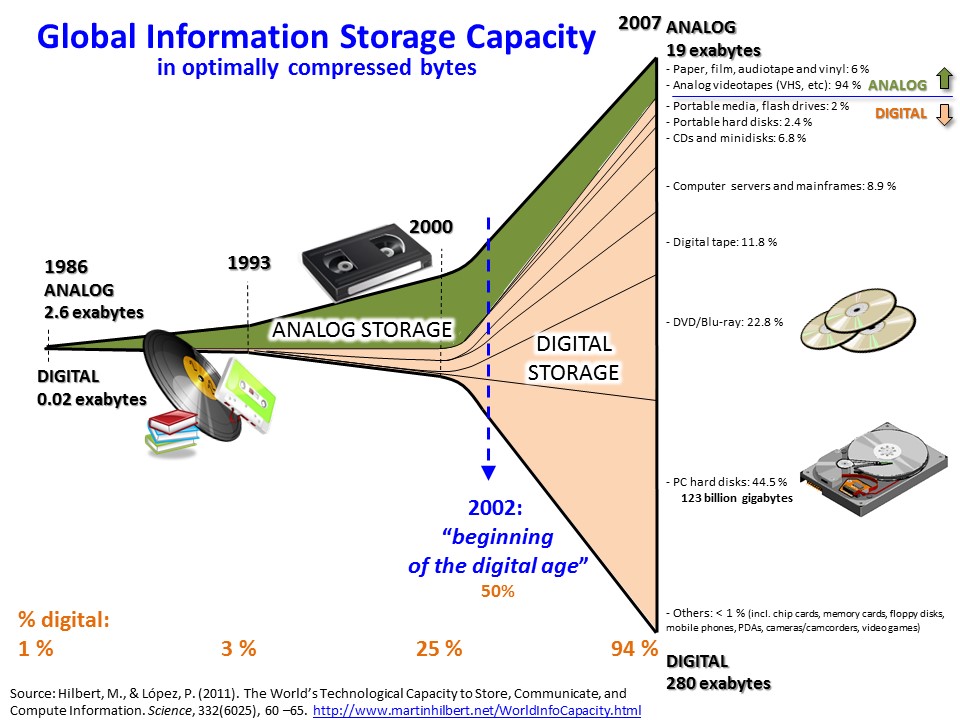
On the other hand, despite all the research being done in the field of distributed systems, a highly scalable universal solution that guarantees data availability for any system working with Big Data (and the associated 3 key concepts) has not yet been found. Access times to physical storage, synchronisation of geo-replicated data, scalability, availability and fault tolerance are some of the pitfalls that must be dealt with. For the time being, partial solutions have been found for certain use cases combining traditional techniques, which opens the door to new professionals with fresh, disruptive ideas.
This is why the discipline of Big Data requires a new cross-disciplinary profile, a professional that will be able to sidestep these pitfalls and extract useful information from large volumes of data. In my opinion, these professionals must be ready to be incorporated at any point in the Big Data life cycle:
- Design of data centres: New-generation data centres must be able to meet the ambitious requirements of Big Data, a new order of magnitude in computing and data storage. For this reason, profiles with advanced knowledge of communications and telematic networks are required, individuals that can understand the different data flows of each application and are capable of designing highly scalable hierarchical architectures that incorporate solutions based on cloud computing.
- Data storage technologies: Once the data centre is designed and deployed, and is capable of efficiently hosting a large amount of data, it is time to select which data storage and processing technology is best suited to each type of application. This is why the market needs professionals who understand the limitations of classic relational systems and who can master new NoSQL technologies such as MongoDB, Hadoop, Cassandra and Neo4J. These professionals must also know how to take advantage of the distributed nature of data to perform parallel computations and thus minimise the volume of data that crosses communications networks.
- Data analysis and Business Intelligence: Data doesn't speak for itself. It’s not enough to have trillions of bytes stored in a super scalable data with the best data storage technology, because the relevant information is not going to appear magically. In order to filter, organise and visualise all this data, it is essential that Big Data professionals master statistical techniques such as inference, regression, clustering and data mining. All this must serve to improve the processes and efficiency of business, and also requires a complementary knowledge in Business Intelligence.
- Application development: Finally, Big Data professionals must have a creative mind that allows them to innovate and benefit from the advantages and possibilities offered by the Big Data paradigm. Without doubt, this will allow them to develop new "data-reliant" applications that improve our daily lives
In conclusion, we’re living in a new era in which data management requires highly qualified cross-disciplinary experts capable of solving the challenges posed by data-dependent applications. It definitely represents a great opportunity for specialisation for recent graduates, who can introduce new ideas that help push the boundaries of Big Data. Not to forget those senior profiles, who will be able to provide valuable experience and insight when it comes to implementing new solutions.