Fog Computing

In our last post, we talked about Edge Computing, explaining what it is, what advantages does it have and how it is used. In this post, we are going to explain a similar technology: Fog Computing, and its relation to Cloud and Edge Computing.
The term Fog Computing was registered by Cisco, who created “Cisco Fog Computing”. While in Cloud Computing the processing and storing is done far from the user (like clouds are far from us), in Fog Computing, such things take place closer to the user (“clouds” close to the ground).
That being said, the difference between them lies in the positioning of the infrastructure:
Edge Computing uses the edge devices of the network to process the data allowing, amongst others, faster response in exchange for low processing power. Cloud computing, in a complete differing position, offers (amongst others), high processing speed but a slower response time. The opposing capabilities are no surprise, as Edge Computing appeared in order to satisfy the needs that Cloud Computing could not reach.
Fog computing is nothing else than the middle solution, a compromise, bringing advantages and disadvantages from both sides. That is to say, whereas edge computing normally occurs directly on the devices where the sensors are attached to or on a device physically close, fog computing can take place anywhere in the LAN: the difference is where the handling of data takes place (as it was previously said).
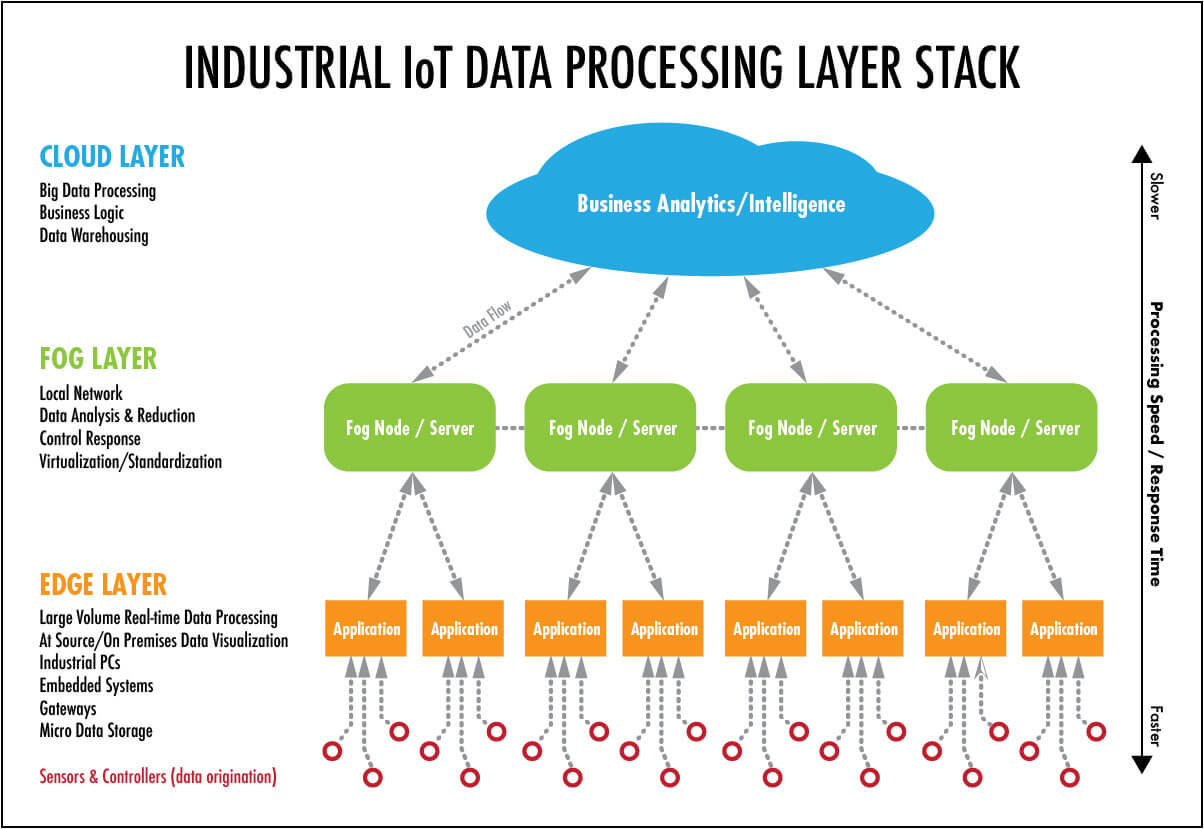
As King, CEO of FogHorn Systems (as its name indicates, they are supporters of fog computing), explained, “edge computing is not scalable, and you can't see across multiple machines or processes with it. Our approach is to move as close to the source as possible without being trapped at the individual machine level.”
In the matter of the advantages and disadvantages of fog computing, the most distinctive is that the flexible limits on where to process data permits for bigger and better infrastructure, with a tradeoff of more latency. That being said, here is a comprehensive table of the attributes and differences between the different types of computing:
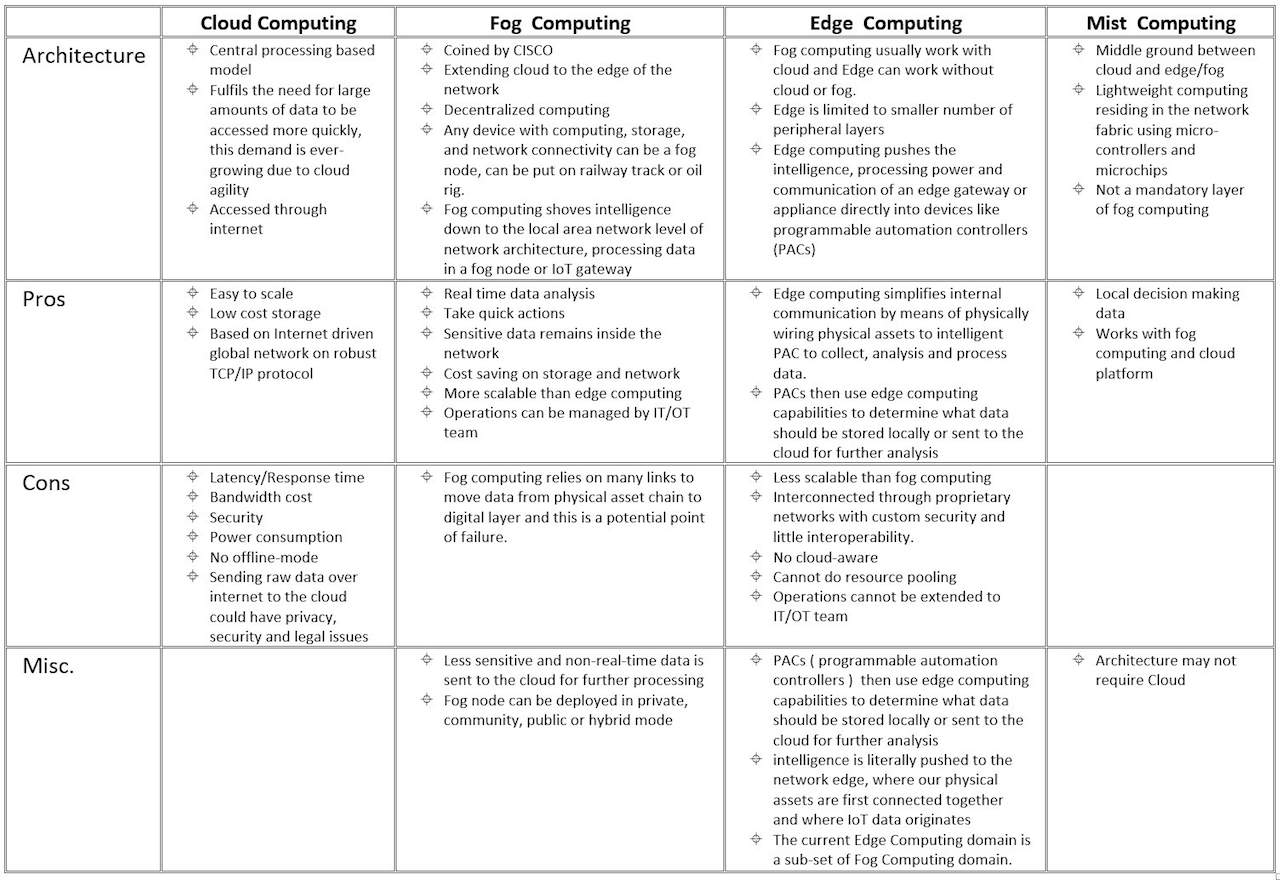
In any case, like edge computing, fog computing is not a substitute of cloud computing, but a supplement: All three technologies can be used to complement and solve each other’s problems. It is also of interest to comment that, in addition to Cloud, Fog and Edge Computing, a new technology has appeared: Mist Computing (which follow the same nomenclature as the first two), a middle ground between Fog and Cloud Computing.
On a final note, there is the OpenFog Consortium, an important consortium spearheaded by many high-tech industry companies and academic institutions (Cisco amongst them), with the idea of promoting and standardizing fog computing.