The dawn of Big Data

Durante las últimas tres décadas, los sistemas de computación por ordenador han experimentado un crecimiento incesable en cuanto a prestaciones y rendimiento, lo que ha propiciado el desarrollo continuo de aplicaciones que dependen de estos sistemas para procesar y almacenar datos. De hecho, las mejoras en cuanto al hardware y las redes de comunicaciones han ampliado el alcance y las dimensiones de estas aplicaciones “dato-dependientes” (desde los clásicos servidores de ficheros hasta Internet, pasando por otros campos como la robótica o la automoción). Esta evolución también ha hecho que las exigencias de los usuarios hacia estos sistemas también hayan ido creciendo con el paso del tiempo, por ejemplo, hoy en día no sería admisible esperar 30 minutos para escuchar una canción descargada de Internet.
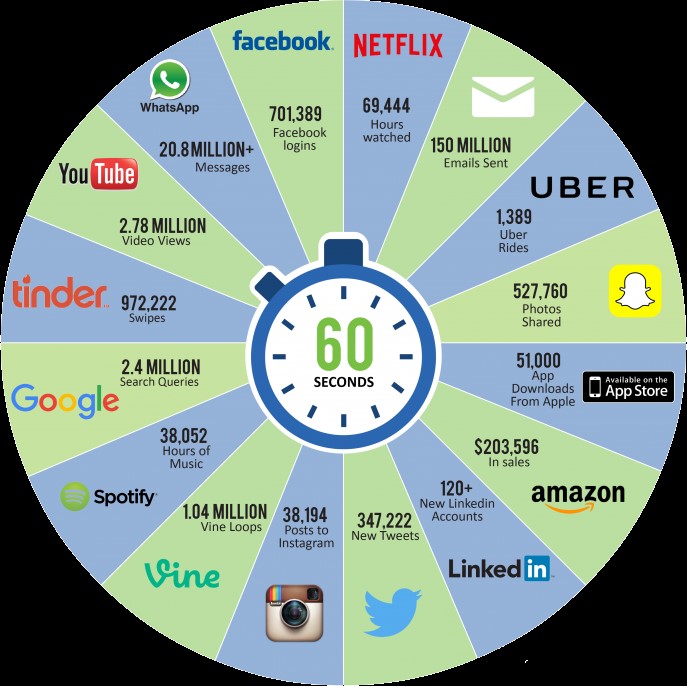
Históricamente, los requerimientos de los usuarios habían ido creciendo proporcionalmente con la tecnología disponible del momento—siempre había habido una caja más grande para empaquetar un nuevo problema más grande. Sin embargo, en los últimos años la cantidad de datos a procesar diariamente, se ha disparado de tal forma que las técnicas tradicionales de procesado y almacenaje de información están quedado rápidamente obsoletas. Por ejemplo, se dice que por en un minuto: se suben 72 nuevas horas de vídeo en YouTube, se almacenan 100 terabytes de información (notificaciones, visitas en páginas, fotos, clicks, etc.) en Facebook, se generan cerca de 500.000 tweets en Twitter, se mandan 200 millones de correos electrónicos y se comparten 350.000 fotografías por Whatsapp. Definitivamente, si uno saca las cuentas de la cantidad de datos que pasan entre nosotros a lo largo del día, los resultados son escalofriantes.

Este nuevo orden de magnitud en los datos ha dado lugar a la definición del concepto Big Data. En general, se dice que éste término hace referencia a cualquier conjunto de datos que satisfaga lo que se conoce como las 3Vs: Volumen, Velocidad y Variedad (algunos autores empiezan a hablar de 6Vs añadiendo Veracidad, Visualización y Valor a las tres anteriores). Dado que estos tres (o seis) parámetros dependen de la naturaleza de cada problema, hoy en día existe una gran confusión acerca de las implicaciones y el alcance del concepto Big Data. En realidad, Big Data no hace referencia únicamente a los datos en sí, sino que también incluye toda la parte de ingeniería, investigación y desarrollo de negocio relacionada con almacenar, procesar y extraer información valiosa de una cantidad ingente de datos. Así pues, estas líneas pretenden aportar un poco más de luz a este concepto (1) justificando qué nos ha llevado a acuñar el término Big Data, (2) enfatizando porqué Big Data es tan diferente a los sistemas tradicionales de gestión de datos y (3) apuntando las oportunidades que el Big Data abre a los nuevos ingenieros y científicos de datos.
En mi opinión, el Big Data ha venido motivado por dos grandes hechos: el aumento del ancho de banda de las conexiones a Internet (el ADSL de hoy en día nos han hecho olvidar los módems de 56Kbps de hace pocos años) y el auge de los smartphones (se estima que 1 de cada 3 personas en el mundo tiene un smartphone). Y es que la combinación de estos dos factores ha llevado a que los usuarios, que no dudan en instalar más y más aplicaciones en sus teléfonos, generen de forma inconsciente infinidad de datos día y noche (calendarios, mensajería, redes sociales, juegos, etc.). Además, estos usuarios, que típicamente desconocen las complejidades tecnológicas que supone procesar tanta información, esperan e incluso exigen una alta calidad en el servicio y tienen muy poca tolerancia a las desconexiones (se calcula que Facebook perdió $500 millones en anuncios por una caída del servicio de 30 minutos), lo que complica el trabajo a los arquitectos de estos sistemas.
A pesar de los últimos avances tecnológicos, los arquitectos de sistemas que diseñan infraestructuras para soportar Big Data han dado con dos limitaciones: el ancho de banda de Internet y el almacenamiento de datos distribuido.
Por un lado, hoy en día todavía es más rápido mandar 100 discos duros con 1 terabyte de información (recuerden, 1 minuto de información que se genera en Facebook) de costa a costa de Estados Unidos a través de una empresa de mensajería que no mandando los datos por Internet. Esta limitación en el ancho de banda de Internet, ha hecho invertir el viejo paradigma en sistemas distribuidos que consistía en acercar los datos (históricamente de volumen reducido) a las unidades de computación (tradicionalmente de coste más elevado); cuando se trata de Big Data, lo que se busca es acercar las unidades de computación (hoy en día de coste reducido) allí donde se generan los grandes volúmenes de datos.
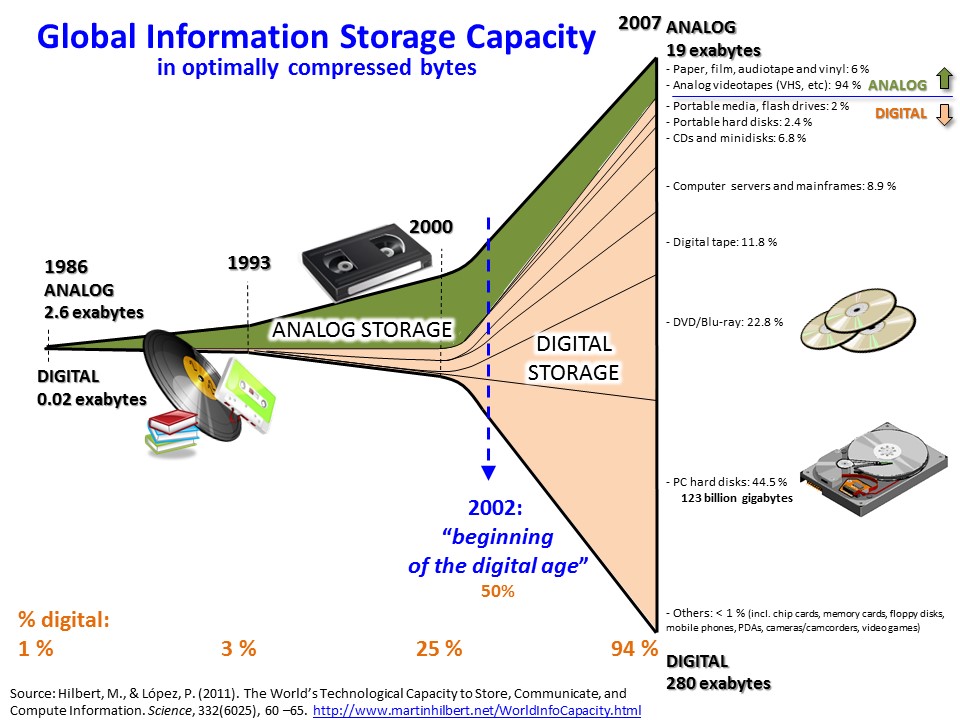
Por otro lado, a pesar de toda la investigación que se está haciendo en el campo de sistemas distribuidos, aún no se ha hallado una solución universal altamente escalable y que garantice la disponibilidad de los datos para cualquier sistema que trabaje con Big Data (y sus 3Vs asociadas). Los tiempos de acceso al almacenamiento físico, la sincronización de datos geo-replicados, la escalabilidad, la disponibilidad, o la tolerancia a fallos, son algunos de los escollos con los que se debe lidiar. Por el momento, se han encontrado soluciones parciales para determinados casos de uso combinando las técnicas clásicas, lo que abre la puerta a nuevos profesionales con ideas frescas y disruptivas.
Por esta razón, la disciplina del Big Data requiere un nuevo perfil interdisciplinar de profesional que sea capaz de dar esquinazo a estos escollos y pueda extraer información útil de grandes volúmenes de datos. Desde mi punto de vista, estos profesionales deberían ser capaces de incorporarse en cualquier punto del ciclo de vida del Big Data:
- Diseño de datacenters: Los centros de datos de nueva generación deben ser capaces de satisfacer los ambiciosos requerimientos del Big Data, un nuevo orden de magnitud en cuanto a computación y almacenamiento de datos. Por eso, se requieren perfiles con conocimientos avanzados de redes de comunicaciones y telemática, que puedan entender los distintos flujos de datos de cada aplicación y sean capaces de diseñar arquitecturas jerárquicas altamente escalables que incorporen soluciones basadas en el cloud computing.
- Tecnologías de almacenamiento de datos: Una vez se tiene diseñado y desplegado el hierro (datacenter) capaz de hospedar eficientemente una gran cantidad de datos, es momento de seleccionar qué tecnología de almacenamiento y procesado de datos se adapta mejor a cada tipo de aplicación. Es por eso que el mercado necesita profesionales que entiendan las limitaciones de los sistemas relacionales clásicos y dominen las nuevas tecnologías NoSQL cómo MongoDB, Hadoop, Cassandra o Neo4J. Además, estos profesionales también deben saber aprovechar la naturaleza distribuida de los datos para realizar computaciones paralelas y así minimizar el volumen de datos que cruza las redes de comunicaciones.
- Análisis de datos y Business Intelligence: Los datos no hablan por sí solos. No basta con tener trillones de bytes almacenados en un datacenter súper escalable sobre el que corre la mejor tecnología de almacenamiento de datos, pues la información relevante no va a aparecer mágicamente. Para filtrar, organizar y visualizar todos estos datos es fundamental que los profesionales del Big Data dominen técnicas estadísticas como por ejemplo la inferencia, la regresión, el clustering o el data mining. Todo ello debe permitir mejorar los procesos y la eficiencia del negocio, lo que además requiere un conocimiento complementario en Business Intelligence.
- Desarrollo de aplicaciones: Finalmente, los profesionales del Big Data deben tener una mente creativa que les permita innovar y beneficiarse de las ventajas y posibilidades que ofrece el paradigma del Big Data. Sin duda esto les permitirá desarrollar nuevas aplicaciones “dato-dependientes” que mejoren nuestro día a día.
En conclusión, estamos viviendo una nueva era en la que la gestión de datos requiere expertos interdisciplinares altamente cualificados que sean capaces de dar solución a los retos que proponen las aplicaciones dato-dependientes. Definitivamente, esta es una gran oportunidad de especialización para los estudiantes recién graduados, los cuales pueden introducir nuevas idees que ayuden a empujar las fronteras del Big Data. Todo ello, sin olvidarse de esos perfiles más sénior, los cuales aportan una experiencia y una visión de la historia muy valiosa a la hora de implementar nuevas soluciones.