Redundancia y alta disponibilidad (II): Parallel Redundancy Protocol

Tras una breve introducción a los conceptos de redundancia y alta disponibilidad, en esta nueva entrada se realizará una explicación sobre uno de los protocolos mencionados anteriormente, el Parallel Redundancy Protocol (PRP) definido dentro del estándar IEC 62439 por el Internacional Electrotechnical Comission. La principal característica de este protocolo es la posibilidad, mediante el uso de dos redes paralelas, de lograr tiempos de recuperación de 0 segundos en caso de producirse un fallo en la red. Un posible esquema de redes PRP es el siguiente: 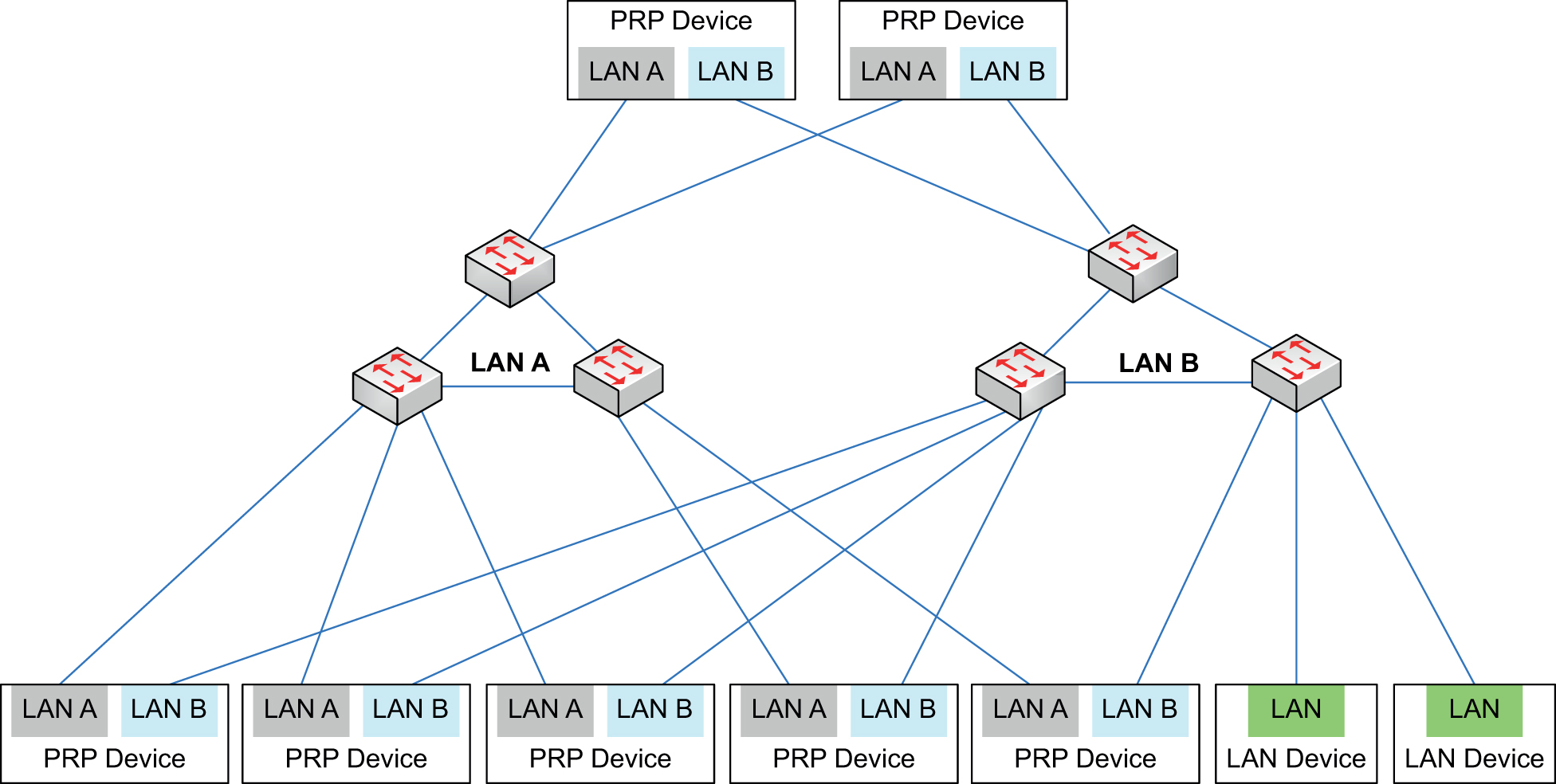 Lo primero que hay que detectar son los diferentes nodos que se presentan:
Lo primero que hay que detectar son los diferentes nodos que se presentan:
- Doubly Attached Node with PRP (DANP): Cada nodo DANP está unido a dos redes LAN independientes de topología similar. Las redes están totalmente separadas, asumiendo que son independientes en cuanto a producirse un fallo en ellas. Además, operan en paralelo, lo cual aporta una capacidad de recuperación sin necesidad de detección (bumpless recovery) y permitiendo comprobar la redundancia constantemente.
- Singly Attached Node (SAN): Son nodos que se conectan a una sola red, por lo que solo pueden comunicarse con otro SAN conectado a la misma red.
- Red Box: Son equipos que permiten a los SAN comportarse como DANP.

Una vez conocidos los nodos, el funcionamiento se basa principalmente en el envío y recepción de paquetes duplicados. Un nodo DANP, o nodo PRP, envía la información a transmitir por las dos interficies que dispone. Estas interficies tendrán la misma dirección IP y la misma dirección MAC, es decir, lógicamente comparten direcciones de nivel 2 y nivel 3. Al enviarse los paquetes por redes diferentes e independientes, no existirá conflicto de direcciones IP o de direcciones MAC. Cuando el receptor recibe un primer paquete, comprueba si se trata de un paquete PRP candidato a ser duplicado, esto lo realiza mediante un proceso de identificación de paquetes que se explicará en la siguiente entrega de Redundancia y alta disponibilidad. En cuanto al tiempo de recuperación de 0 milisegundos, esto es debido a que al estar totalmente duplicada la red, si se produce un fallo en una de ellas y en ese momento se genera una señal de alarma en alguno de los equipos conectados a un nodo PRP, no necesita detectar el error y reconfigurar la red ya que envía la alarma por ambos caminos, estén o no dañados. La principal desventaja de este protocolo es el alto coste que supone ya que es duplicar en su totalidad una red de comunicaciones, además del también elevado coste que supondría aumentar la escalabilidad del sistema. Como ya hemos comentado antes, el próximo capitulo se tratará el sistema de gestión de paquetes duplicados en un nodo y los mecanismos que utiliza.