Cloud vs Fog vs Edge Computing
Cloud Computing
Cloud computing is a general term for the provision of services over the Internet. This enables companies to consume computing resources as a utility rather than having to build, manage and maintain computing infrastructures in their offices.
Thus, cloud computing is a new technology that seeks to have all our files and information on the Internet, without worrying about having enough capacity to store or process information on our computer. In this way, all the information, processes, data, etc., are located within the Internet network and not in the local network of the company in question, so that everyone can access the information without having a large infrastructure if desired.
When it comes to cloud computing, however, a distinction needs to be made between three different types of offering this service:
- Infrastructure as a Service (IaaS): An ordinary web host is a simple example of IaaS, where you pay a monthly subscription or a fee per gigabytes or megabytes consumed. This means that you are buying access to raw computing hardware over the network, such as servers or storage.
- Software as a Service (SaaS): means that you use a complete application that runs on someone else's system, these can be, for example: web-based email and Google documents.
- Platform as a Service (PaaS): means being able to develop applications using web-based tools to run on software and hardware systems provided by another company.
Fog Computing
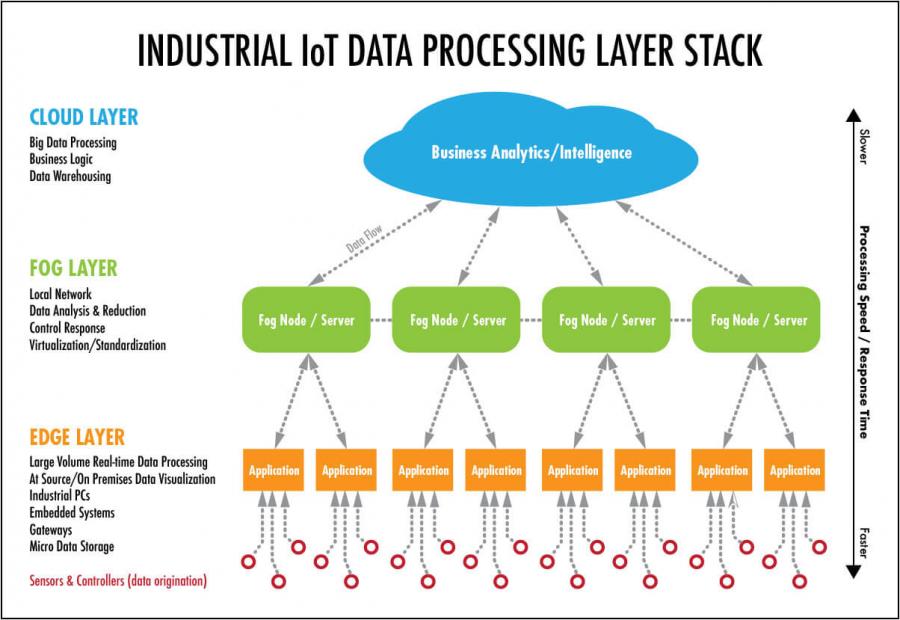
The concept of Fog Computing refers to a decentralized structure in which resources, including data and applications, are placed in a logical place between the cloud and the source of the data.
This implies that it is possible to bring the services that analyze this data closer to its origin (since the Fog is closer to the origin of the data than the Cloud). This makes it possible to improve overall performance thanks to a reduction in the distance that data travels on the network, thus achieving greater efficiency.
Fog Computing emerges as a natural extension of Cloud Computing, driven above all by the growing demand in the IoT sector to be able to process large amounts of data with very low latency and reducing costs as much as possible. The concept of Fog Computing, however, is not that different from Cloud Computing in the sense that it continues to comply with a paradigm in which we have data, storage, and applications on a distant server and not locally. Thus, Fog Computing could be defined as a Cloud Computing closer to the origin of the data, or what is the same, a cloud that approaches the earth (hence the name fog).
It can be said that Fog Computing is an intermediary between the Cloud infrastructure and the IoT devices. By performing some of the processing close to the origin, the data to be sent to the cloud is pre-filtered. In this way, not only the latency is reduced, but the data load to the cloud is reduced, being able to reduce the bandwidth requirements of the company (and thus reduce the cost of this service).
Edge Computing
There are currently millions of devices in the IoT industry that are solely responsible for collecting information but do nothing with it. They send it to the cloud, where large data centers process it.
This passive operation of some devices is what the so-called Edge Computing aims to change, a type of philosophy applicable especially in business and industrial scenarios that provides much more autonomy to all these devices.
The so-called Edge Computing allows data produced by IoT devices to be processed closer to where it is created instead of sending it to the cloud or even fog.
This has a fundamental advantage, as it allows organizations to analyze important data in near real time, which is increasingly necessary and beneficial in many industries and businesses every day.
Ericsson predicts that there will be a total of 30 billion IoT devices by 2021. Thus, although the IEEE has stated that the figures are very difficult to measure now, the truth is that many of these connected devices will have the capacity not only to collect, but also to process data, following the philosophy of Edge Computing.
Conclusion
It cannot be said that one of the three methodologies is better than any other, since none of the three is better than another, and none of the three is usually used alone. In other words, in practice, all (or almost all) of these methodologies are handled jointly, following a hierarchy.
The data that needs to be processed with a lower latency (practically in real time) are processed in the same sensors or their local network (Edge Computing). Once this data has been processed, its results can be used for some tasks or sent to the Internet. If it needs to be sent to the Internet, normally much less data is sent than would have been sent if this initial data processing had not been carried out. Thus, some data is sent to the fog, where it is processed and new conclusions are drawn, sometimes considering a historical data that is stored in a database in the fog (Fog Computing). Finally, this data, which has been doubly filtered, is sent to the cloud, where it is stored to maintain a history of the data and where it can be processed again to obtain new conclusions or activate an event based on these (Cloud Computing).
In conclusion, each of the three methodologies offers certain advantages over the rest, but also has certain disadvantages. The best way to be able to take advantage of all the advantages, without being affected by the disadvantages and being able to process the data in the most efficient way possible, as well as reduce costs to the maximum is by creating a well-structured hierarchy for data processing and use of the three methodologies together.
Authors
Joan Farràs
Ferran Montoliu