GTM presentation at the 5th ECCOMAS Young Investigators Conference (YIC2019)

The European Community on Computational Methods in Applied Sciences (ECCOMAS) organized the 5th ECCOMAS Young Investigators Conference (YIC2019) from September 1st through 6th, 2019, at AGH University of Science and Technology, Krakow, Poland.
The member of the GTM Dr. Arnau Pont presented a work made at YIC2019 in collaboration with Dr. Marc Arnela and Prof. Oriol Guasch about the numerical production of voice. The work addressed the generation of the syllable /sa/ using finite element codes. It applied a novel approach developed by GTM researchers in which the Lighthill’s quadrupole acoustic source term, typically obtained from the resolution of the incompressible Navier-Stokes equations, is modelled with a random distribution of Kirchhoff's spinning vortices. This allowed for a large reduction of the computational costs.
The reference of the conference contribution is:
- Arnau Pont, Marc Arnela and Oriol Guasch (2019); “Finite element generation of vowel-sibilant utterances using random distributions of Kirchhoff’s vortices and simplified vocal tract geometries”, ECCOMAS Young Investigators Conference, September 1-6, Krakow, Poland
with abstract:
The production of a single sibilant sound like /s/ can be simulated with standard hybrid computational aeroacoustics (CAA) approaches, although supercomputer facilities are necessary to generate a few milliseconds of sound [1-3]. Therefore, attempting the synthesis of more complex utterances, like syllables containing vowels and sibilants, may appear as a prohibitive task. However, it has recently been proposed in [4] to skip the resolution of the incompressible Navier-Stokes equations in the first step of hybrid CAA, by modelling Lighthill’s quadrupole acoustic source term with a random distribution of Kirchhoff's spinning vortices [5]. This shall facilitate the generation of a syllable sound like /sa/, because the procedure now only involves solving the linear wave equation in mixed form in an ALE framework, as done in the production of vowel-vowel utterances like diphthongs [6]. No computational fluid dynamics step is thus required. The goal of this work is to present some first steps towards the three-dimensional (3D) simulation of the sequence /sa/. 3D simplified static vocal tract geometries are first constructed for that purpose, using the 1D area functions in [7]. Then, we resort to linear interpolation from the vocal tract geometry of an /s/ to that of an /a/ to generate the dynamic vocal tract corresponding to the sound sequence /sa/. Figure 1 shows the static geometries obtained for sibilant /s/ and vowel /a/. At the bottom of the figure we present their acoustic pressure spectra. That of vowel /a/ has been generated by imposing a train of glottal pulses at the glottis cross-section, which induces acoustic resonances when waves propagate inside the vocal tract. Besides, the spectrum of sibilant /s/ has been computed by activating a Kirchoff’s vortex distribution between the interdental space and the lower lip in the vocal tract. Whereas solving the wave equation in mixed form [8-9] suffices for producing sounds /s/ and /a/ individually, one needs to set the equation in an ALE framework to generate the sequence /sa/ [6]. That would be the main output of this work. Also, we will show that one can collect the computed acoustic pressure at a point close to the mouth exit and make an audio file to listen to the computationally generated sequence /sa/. That would have proved unreachable with a standard hybrid CAA approach.
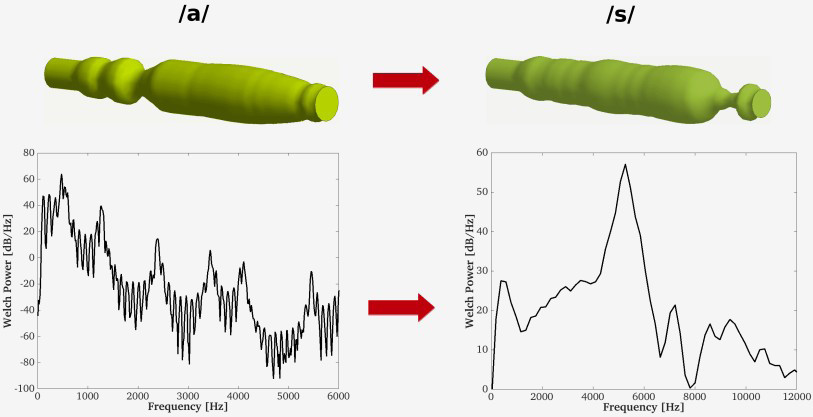
Figure 1: Schematical transition from an open configuration corresponding to the vowel /a/ to that of sibilant /s/ using a simplified 3D axisymmetric geometry (top). Frequency spectra at the beginning and the end of the sequence (bottom).
A critical point regarding the generation of /sa/ with the above described approach concerns the accuracy of the Kirchhoff’s vortex distribution as a proper acoustic source term for /s/. In Figure 2, we show the sibilant /s/ averaged spectrum after 10 runs of the random model used to activate and deactivate the vortices. As observed in the figure, the typical spectral shape of an /s/ is recovered, having a small low frequency distribution that slightly increases peaking close to 6 kHz. This shows that the simplified aeroacoustic source model is rather general and not only valuable in complex realistic vocal tract geometries (see [1]), but also in simplified ones. That allows one to generate vowel-sibilant utterances with confidence using a single laptop PC.
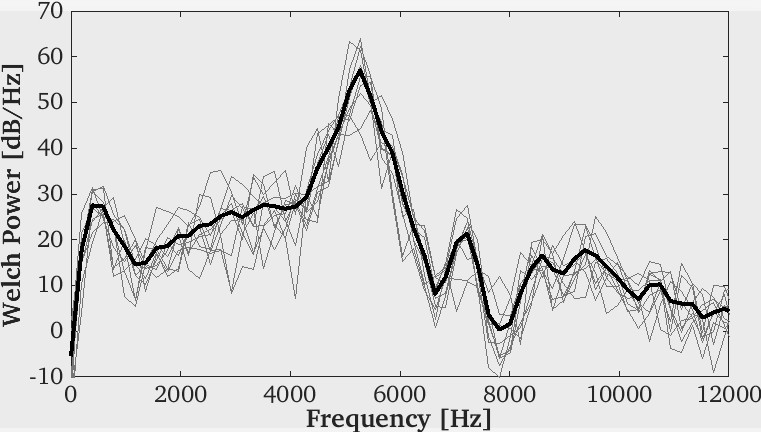
Figure 2: Averaged Welch power spectrum of the sibilant /s/ in a simplified axisymmetric geometry using a tailored distribution of Kirchhoff’s vortices.
REFERENCES
[1] A. Pont, O. Guasch, J. Baiges, R. Codina, A. van Hirtum, Computational Aeroacoustics to identify sound sources in the generation of sibilant /s/, International Journal for Numerical Methods in Biomedical Engineering, 35 (1), 31-53 (2019).
[2] T. Yoshinaga, K. Nozaki and S. Wada, Experimental and numerical investigation of the sound generation mechanisms of sibilant fricatives using a simplified vocal tract model, Physics of Fluids. 30 (3), 035104 (2018).
[3] O. Guasch, A. Pont, J. Baiges, R. Codina, Concurrent finite element simulation of quadrupolar and dipolar flow noise in low Mach number aeroacoustics, Computers & Fluids, 133, 129-139 (2016).
[4] A. Pont, O. Guasch, M. Arnela, Finite Element Generation of sibilants /s/ and /z/ using random distributions of Kirchhoff’s vortices, International Journal for Numerical Methods in Biomedical Engineering, submitted (2019).
[5] M. S. Howe, Contributions to the theory of aerodynamic sound, with application to excess jet noise and theory of the flute, Journal of Fluid Mechanics, 71(4), 625-673 (1975).
[6] O. Guasch, M. Arnela, R. Codina, H. Espinoza, A stabilized finite element method for the mixed wave equation in an ALE framework with application to diphthong production, Acta Acustica united with Acustica, 102(1), 94-106 (2016).
[7] D. Beautemps, P. Badin and R. Laboissière, Deriving vocal-tract area functions from midsagittal profiles and formant frequencies: A new model for vowels and fricative consonants based on experimental data, Speech Communication, 16 (1), 27-47 (1995).
[8] R. Codina, Finite element approximation of the hyperbolic wave equation in mixed form, Computer Methods in Applied Mechanics and Engineering, 197(13-16), 1305-1322 (2008).
[9] S.Badia, R. Codina, H. Espinoza, Stability, convergence and accuracy of stabilized finite element method for the wave equation in mixed form. SIAM Journal of Numerical Analysis, Vol. 52, 1729-1752 (2014).
ACKNOWLEDGMENTS
This work has been supported by the Agencia Estatal de Investigación (AEI) and FEDER, EU, through project GENIOVOX (TEC2016-81107-P). The third author would also like to thank l'Obra Social de la Caixa and the Universitat Ramon Llull for their backing under grant 2018-URL-IR2nQ-031. The authors also gratefully acknowledge the International Center for Numerical Methods in Engineering for their support with the computational code FEMUSS.