Simulation of diphthongs using 3D vocal tract geometries obtained from Magnetic Resonance Imaging
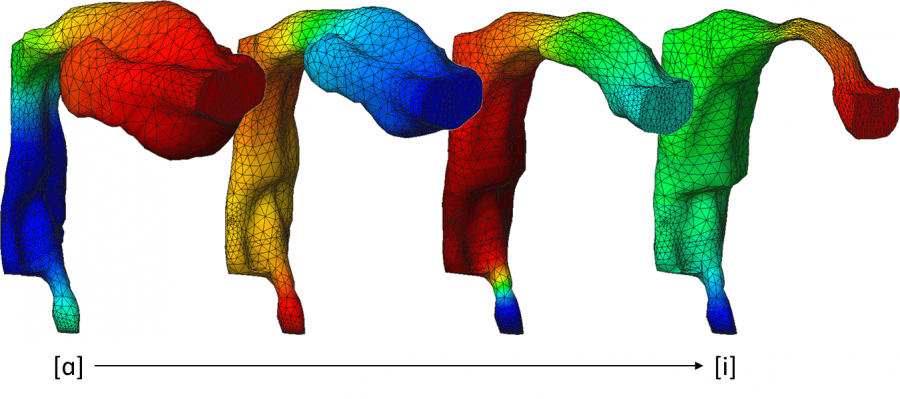
When we produce the diphthong [ɑi] we move the tongue, jaw and lips (among other articulators) to change the vocal tract shape from that of an [ɑ] to that of an [i]. At the same time, the vocal cords generate sound waves that propagate through this dynamic vocal tract, which emerge from the lips and result in the generated sound.
Researchers from the acoustics area of the GTM, Dr. Marc Arnela and Prof. Oriol Guasch, in collaboration with two researchers from the KTH Royal Institute of Technology in Stockholm, Dr. Saeed Dabbaghchian and Prof. Olov Engwall, have simulated for the first time this physical phenomenon in a realistic three-dimensional (3D) vocal tract. To do so, they have developed a dynamic 3D vocal tract representation based on static vowel vocal tract geometries obtained from Magnetic Resonance Imaging (MRI). The propagation of acoustic waves in the dynamic vocal tract was simulated using an in-house 3D finite element code for acoustics.
More details can be found in the following paper:
- Marc Arnela, Saeed Dabbaghchian, Oriol Guasch and Olov Engwall (2019), “MRI-based vocal tract representations for the three-dimensional finite element synthesis of diphthongs”, IEEE/ACM Transactions on Audio, Speech and Language Processing, 27 (12), pp 2173-2182, https://doi.org/10.1109/TASLP.2019.2942439
with abstract:
The synthesis of diphthongs in three-dimensions (3D) involves the simulation of acoustic waves propagating through a complex 3D vocal tract geometry that deforms over time. Accurate 3D vocal tract geometries can be extracted from Magnetic Resonance Imaging (MRI), but due to long acquisition times, only static sounds can be currently studied with an adequate spatial resolution. In this work, 3D dynamic vocal tract representations are built to generate diphthongs, based on a set of cross-sections extracted from MRI-based vocal tract geometries of static vowel sounds. A diphthong can then be easily generated by interpolating the location, orientation and shape of these cross-sections, thus avoiding the interpolation of full 3D geometries. Two options are explored to extract the cross-sections. The first one is based on an adaptive grid (AG), which extracts the cross-sections perpendicular to the vocal tract midline, whereas the second one resorts to a semi-polar grid (SPG) strategy, which fixes the cross-section orientations. The finite element method (FEM) has been used to solve the mixed wave equation and synthesize diphthongs [ɑi] and [ɑu] in the dynamic 3D vocal tracts. The outputs from a 1D acoustic model based on the Transfer Matrix Method have also been included for comparison. The results show that the SPG and AG provide very close solutions in 3D, whereas significant differences are observed when using them in 1D. The SPG dynamic vocal tract representation is recommended for 3D simulations because it helps to prevent the collision of adjacent cross-sections.
Acknowledgements:
The authors would like to acknowledge David Vila, who helped in the development of the 1D synthesiser during his BSc final project (supervised by Dr. Marc Arnela). This research has been supported by the Agencia Estatal de Investigación (AEI) and FEDER, EU, through project GENIOVOX TEC2016-81107-P. The third author would like to thank l’Obra Social de la Caixa and the Universitat Ramon Llull for their support under grant 2018-URL-IR2nQ-031.