Simulation of the voice sequence /asa/ at the International Congress on Acoustics (ICA 2019)
Figure 1 - Dr. Marc Arnela presenting at the International Congress on Acoustics (ICA 2019).
The member of the GTM Dr. Marc Arnela presented at the International Congress on Acoustics (ICA 2019), held in Aachen (Germany) from 09-13 September, a work made in collaboration with Prof. Oriol Guasch about the numerical production of voice.
That work addressed the generation of the sequence /asa/ using finite element codes. In particular, the work proposed a simplified aeroacoustic source model to produce the sibilant /s/. That model, combined with current knowledge on diphthong simulation (for instance, /ai/), allowed to simulate for the first time the sequence /asa/ in a 3D vocal tract.
The oral presentation was done by Dr. Marc Arnela.
The reference of the paper is:
- Marc Arnela and Oriol Guasch (2019); “Finite element simulation of /asa/ in a three-dimensional vocal tract using a simplified aeroacoustic source model”, 23rd International Congress on Acoustics, September 9-13, Aachen, Germany
with abstract:
The numerical simulation of fricative sounds in three-dimensional (3D) vocal tracts typically involves hybrid Computational Aeroacoustics (CAA) approaches. Unfortunately, those are very costly and require from super-computer facilities to produce a mere few milliseconds of sound. The problem becomes prohibitive if one not only aims at generating a single fricative, but also sequences containing both, vowels and fricatives. It then seems wise to try to approximate somehow the flow noise sources, so that only an acoustic simulation becomes necessary. That avoids the very demanding computational fluid dynamics step in CAA. Aeroacoustic sources can be modeled to different levels of precision. In this work, it is suggested to follow a similar methodology to that in one-dimensional (1D) techniques, but applied to 3D dynamic vocal tracts. Vowel sounds are produced introducing glottal pulses at the vocal tract entrance (glottis), while monopole and dipole sources consisting of white noise are activated in the region where a fricative sound is generated. Acoustic wave propagation in a 3D dynamic vocal tract is simulated using a stabilized Finite Element Method (FEM) for the wave equation in mixed form, set in an Arbitrary Lagrangian-Eulerian (ALE) framework. The sequence /asa/ is produced as an exemple.
Link: http://pub.dega-akustik.de/ICA2019/data/articles/000460.pdf
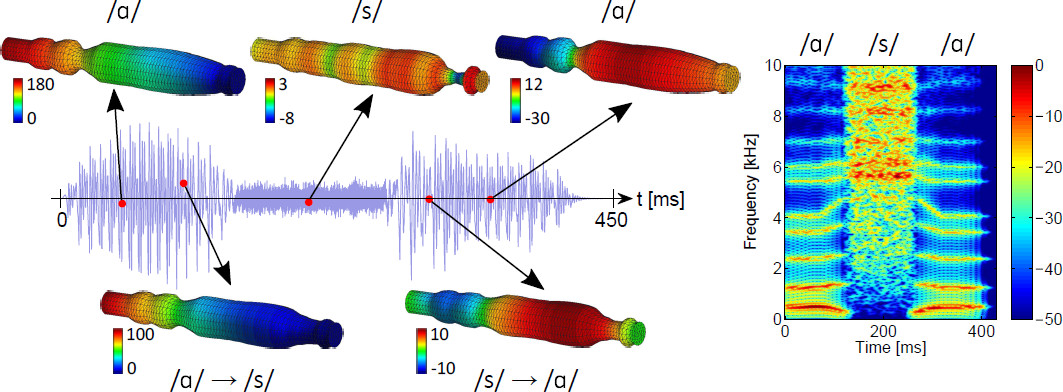
Figure 2 - Evolution of the acoustic pressure for the FEM simulated sequence /asa/ with some snapshots showing the acoustic pressure (in Pa) within the vocal tract. The spectrogram of /asa/ is represented in the right panel (in dBs).
This research has been supported by the Agencia Estatal de Investigación (AEI) and FEDER, EU, through project GENIOVOX TEC2016-81107-P. Prof. Oriol Guasch would also like to thank l’Obra Social de la Caixa and the Universitat Ramon Llull for their support under grant 2018-URL-IR2nQ-031.