Simulation of vowel-vowel utterances using a 3D biomechanical-acoustic model
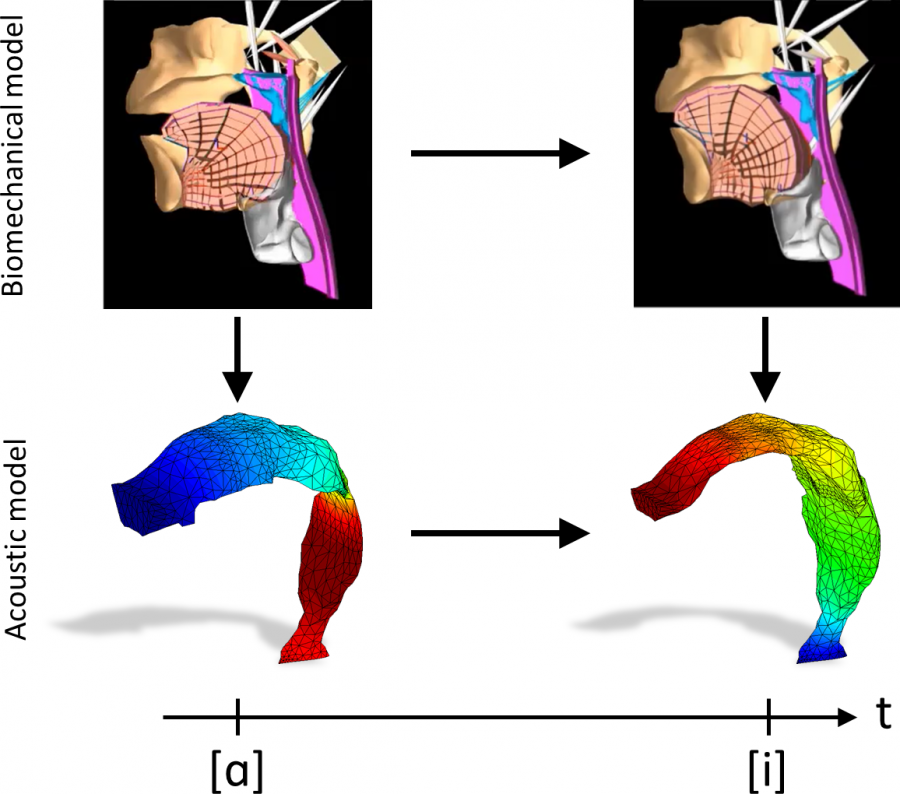
When we speak, the vocal cords generate acoustic waves that propagate through a 3D vocal tract that deforms over time thanks to different articulators like the tongue. This physical phenomenon can be simulated in a computer, but needs a detailed model for the vocal tract and an appropriate acoustic model to account for the propagation of acoustic waves.
The researchers from the acoustics area of the GTM, Dr. Marc Arnela and Prof. Oriol Guasch, together with researchers from the Royal Institute of Technology (KTH) in Stockholm, Dr. Saeed Dabbaghchian and Prof. Olov Engwall, have generated for the first time vowel-vowel sequences combining the 3D biomechanical model Artisynth with the in-house 3D numerical code for acoustics developed by the GTM. Some diphthongs like /ai/ have been generated as examples, simulating in 3D from the activation of the muscles that move the tongue, to the propagation of sound waves that generate the emitted sound.
The details of this work have been recently published in the International Journal for Numerical Methods in Biomedical Engineering (https://doi.org/10.1002/cnm.3407)
- Saeed Dabbaghchian, Marc Arnela, Olov Engwall and Oriol Guasch (2021), "Simulation of vowel-vowel utterances using a 3D biomechanical-acoustic model", International Journal for Numerical Methods in Biomedical Engineering, 37, e3407.
Abstract:
A link is established between biomechanical and acoustic 3D models for the numerical simulation of vowel‐vowel utterances. The former rely on the activation and contraction of relevant muscles for voice production, which displace and distort speech organs. However, biomechanical models do not provide a closed computational domain of the 3D vocal tract airway where to simulate sound wave propagation. An algorithm is thus proposed to extract the vocal tract boundary from the surrounding anatomical structures at each time step of the transition between vowels. The resulting 3D geometries are fed into a 3D finite element acoustic model that solves the mixed wave equation for the acoustic pressure and particle velocity. An arbitrary Lagrangian–Eulerian framework is considered to account for the evolving vocal tract. Examples include six static vowels and three dynamic vowel‐vowel utterances. Plausible muscle activation patterns are first determined for the static vowel sounds following an inverse method. Dynamic utterances are then generated by linearly interpolating the muscle activation of the static vowels. Results exhibit nonlinear trajectory of the vocal tract geometry, similar to that observed in electromagnetic midsagittal articulography. Clear differences are appreciated when comparing the generated sound with that obtained from direct linear interpolation of the vocal tract geometry. That is, interpolation between the starting and ending vocal tract geometries of an utterance, without resorting to any biomechanical model.
This work has been supported by the Agencia Estatal de Investigación (AEI) and FEDER, EU, through project GENIOVOX TEC2016-81107-P.