Cloud vs Fog vs Edge Computing
Cloud Computing
La computación en la nube es un término general para la prestación de servicios a través de Internet. Esta permite a las empresas consumir recursos informáticos como una utilidad en lugar de tener que construir, gestionar y mantener infraestructuras de computación en sus oficinas.
Así pues, la computación en la nube es una tecnología nueva que busca tener todos nuestros archivos e información en Internet, sin preocuparse por poseer la capacidad suficiente para almacenar o procesar información en nuestro ordenador. De este modo, toda la información, procesos, datos, etc., se localizan dentro de la red de Internet y no en la red local de la empresa en cuestión, por lo que todo el mundo puede acceder a la información sin poseer una gran infraestructura si así se desea.
Cuando se habla de computación en la nube, sin embargo, hace falta hacer una distinción entre tres tipos diferentes de ofrecer este servicio:
- Infraestructura como Servicio (IaaS): un alojamiento web ordinario es un simple ejemplo de IaaS, en el que pagas una suscripción mensual o una tarifa por gigabytes o megabytes consumidos. Esto quiere decir que estás comprando el acceso al hardware de computación en bruto través de la red, tales como servidores o almacenamiento.
- Software como Servicio (SaaS): significa que se utiliza una aplicación completa que se ejecuta en el sistema de otra persona, estos pueden ser, por ejemplo: el correo electrónico basado en web y documentos de Google.
- Plataforma como Servicio (PaaS): significa poder desarrollar aplicaciones haciendo uso de herramientas basadas en la web para que se ejecuten en sistemas de software y hardware proporcionados por otra compañía.
Fog Computing
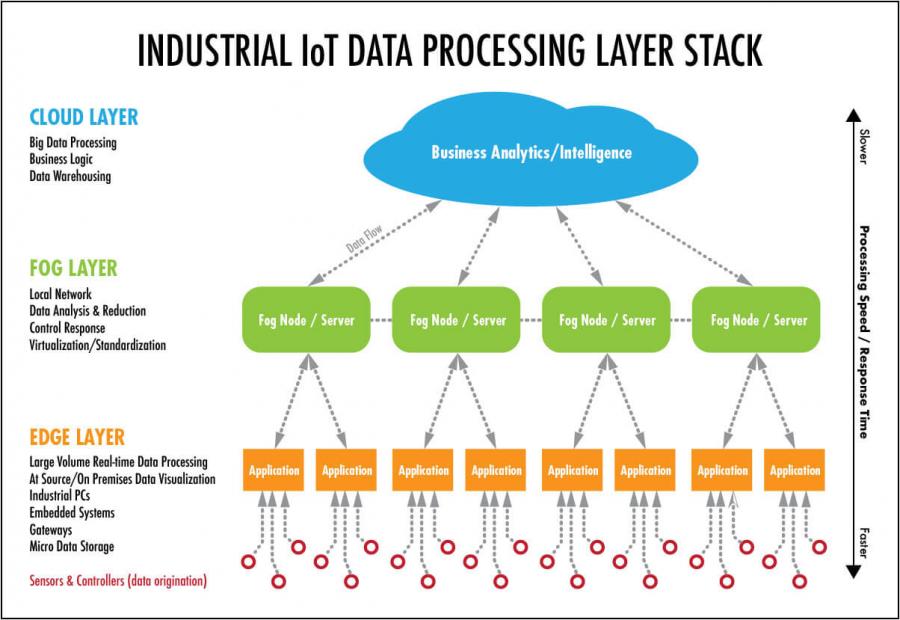
El concepto de Fog Computing hace referencia a una estructura descentralizada en la que los recursos, incluyendo datos y aplicaciones, se sitúan en un lugar lógico entre la nube y el origen de los datos.
Esto implica que es posible llevar los servicios que analizan estos datos más cerca de su origen (ya que el Fog está más cerca del origen de los datos que el Cloud). Esto permite mejorar las prestaciones globales gracias a una reducción de la distancia que recorren los datos en la red, consiguiendo así una mayor eficiencia.
El Fog Computing surge como una extensión natural del Cloud Computing, impulsada sobre todo por la creciente demanda del sector IoT de poder procesar grandes cantidades de datos con una latencia muy baja y reduciendo los costes al máximo. El concepto de Fog Computing, sin embargo, no es tan diferente del Cloud Computing en el sentido de que sigue cumpliendo con un paradigma en el que tenemos los datos, el almacenamiento y las aplicaciones en un servidor distante y no en local. Así pues, se podría definir al Fog Computing como un Cloud Computing más cercano al origen de los datos, o lo que es lo mismo, una nube que se acerca a la tierra (de ahí el nombre de niebla).
Se puede decir que Fog Computing es un intermediario entre la infraestructura Cloud y los dispositivos IoT. Al realizar parte del procesamiento cerca del origen, se hace un filtrado previo de los datos que se enviarán a la nube. De esta forma, no sólo se reduce la latencia, sino que se reducen la carga de datos hacia la nube, pudiendo reducir los requisitos de ancho de banda de la empresa (y así reducir el coste de este servicio).
Edge Computing
Actualmente hay millones de dispositivos de la industria IoT que se encargan únicamente de recoger información, pero no hacen nada con ella. La envían a la nube, donde grandes centros de datos la procesan.
Este funcionamiento pasivo de algunos dispositivos es lo que pretende cambiar la llamada Edge Computing, un tipo de filosofía aplicable especialmente en escenarios empresariales e industriales que aporta mucha más autonomía a todos estos dispositivos
La llamada Edge Computing permite que los datos producidos por los dispositivos de IoT se procesen más cerca de donde se crean en lugar de enviarlos a la nube o incluso a la niebla.
Esto tiene una ventaja fundamental, ya que permite a las organizaciones analizar los datos importantes casi en tiempo real, lo que cada día es más necesario y beneficioso en muchas industrias y negocios.
Ericsson prevé que en 2021 haya un total de 30.000 millones de dispositivos IoT. Así pues, aunque desde el IEEE haya afirmado que las cifras son de momento muy difíciles de medir, lo cierto es que muchos de estos dispositivos conectados tendrán capacidad no sólo de recolección, sino de procesado de datos, siguiendo con la filosofía de la Edge Computing.
Conclusión
No se puede decir que una de las tres metodologías es mejor que alguna otra, ya que realmente ninguna de las tres es mejor que otra ni ninguna de las tres se suele utilizar sola. Es decir que, en la práctica, se manejan todas (o casi todas) estas metodologías de manera conjunta, siguiendo una jerarquía.
Los datos que necesitan ser procesadas con una menor latencia (prácticamente a tiempo real) se procesan en los mismos sensores o la red local de estos (Edge Computing). Una vez procesadas estos datos, sus resultados se pueden usar para alguna tarea o enviarse a Internet. En caso de necesitar enviarse a Internet, normalmente se envían muchos menos datos de los que se hubieran enviado si no se hubiera realizado este procesado inicial de los datos. Así pues, algunos datos se envían a la niebla, donde se procesan y se extraen unas nuevas conclusiones, en ocasiones teniendo en cuenta un histórico de datos que tiene almacenado en una base de datos en la niebla (Fog Computing). Finalmente, estos datos, las cuales han sido doblemente filtradas, se envían a la nube, donde se almacenan para mantener un histórico de los datos y donde se pueden procesar de nuevo para obtener nuevas conclusiones o activar algún evento a partir de estas (Cloud Computing).
En conclusión, cada una de las tres metodologías ofrece ciertas ventajas sobre el resto, pero también presenta ciertas desventajas. La mejor manera de poder aprovechar todas las ventajas, sin que nos afecten las desventajas y pudiendo procesar los datos de la forma más eficiente posible, así como reducir los costes al máximo es creando una jerarquía bien estructurada por el procesado de los datos y en uso de las tres metodologías de manera conjunta.
Autores
Joan Farràs
Ferran Montoliu